Fun AI
Shakespearean Sonnet Generator
Natural Language Processing (NLP) is a vast field that has applications in language translation, speech recognition, sentiment analysis, text understanding, text classification, text generation, etc. One fun project in NLP is to build a model that generates machine-written sonnets in the style of William Shakespeare.
In this project, I built and trained Recurrent Neural Networks (RNNs) and Hidden Markov Models (HMMs) to generate sonnets of Shakespeare's writing style. Models were trained on all 154 Shakespearean sonnets and an additional dataset, Amoretti written by Edmund Spenser, a contemporary Shakespearean poet.
Shakespeare's sonnets follow very specific patterns and are great for generative models. Format-wise, a sonnet is 14 lines long, splitting into 3 quatrains, each with 4 lines, ended by a couplet of 2 lines. Shakespearean sonnets also have a particular rhyme scheme, "ABAB CDCD EFEF GG". Meter-wise, they follow iambic pentameter, where a stressed syllable is followed by an unstressed syllable. And each line has 10 syllables in total (mostly).
 Top 50 words in Shakespeare's sonnets.
Top 50 words in Shakespeare's sonnets.For RNNs, I trained my models using character-based tokenization and sonnet-based sequencing. My best RNN consists of 3 LSTM hidden layers of 600 units, each accompanied by 20% dropout. The output is a fully-connected dense layer with a softmax nonlinearity. The model is trained to minimize categorical cross-entropy loss with the ‘adam’ optimizer.
Below is one example generated sonnet. In this case, we can see that the poems are not too bad! In terms of sentence structures and phrases. And we see recurring themes/keywords throughout. But they do not follow the specific syllable count, rhyme scheme or iambic pentameter.
Then the powerful king put to the test,
Both soul doth say thy show,
The worst of worth the words of weather ere:
And with the crow of well of thine to make thy large will more.
Let no unkind, no fair beseechers kill,
Though rosy lips and lovely yief.
Her wratk doth bind the heartost simple fair,
That eyes can see! take heed (dear heart) of this large privilege,
And she with meek heart doth please all seeing,
Or all alone, and look and moan,
She is no woman, but senseless stone.
But when i plead, she bids me play my part,
And when i weep, in all alone,
That he with meeks but best to be.
For HMMs, I trained my models using word-based tokenization and line-based sequencing. My best HMM contains 32 hidden states. Below is one example generated sonnet. In this case, I generated poems that follow the Shakespearean rhyme scheme and syllable count. But poems contain mostly only valid phrases. They are not good poems.
The large numbers must due did be you sweet
Love thou have black heaven love hair was stand
Beauteous the large least in the building seat
Child be numbers to fair fearless men brand
The happy dress came now would my thy gait
It they and that clay all she glory that
Thou was me should tears in they art the mate
The message and thine once make thine loud at
Beseechers rack for it miss print said thou
Sue glorious mine freshly affections growth
Praise to have same feeds in tongue and then how
Back seeing the black sail so my is loath
Thoughts ever in in one in thine been turn
True none thou wolf ever or she return
Lastly, I named my Shakespearean sonnet-writing AI, William-wanna-shake-pear.

[Github: https://github.com/litingxiao/William-wanna-shake-pear] Back to top
MovieLens Dataset Visualization Using Matrix Factorization
In this project, I observe and interpret the MovieLens dataset both in the exploratory data analysis phase and after matrix factorization using different singular value decomposition (SVD) methods. The MovieLens dataset consists of 100,000 ratings from 943 users on 1682 movies, where each user has rated at least 20 movies.
I first group together duplicate entries to clean the data. In data exploration, I find out that the data are skewed towards higher ratings and fewer number of ratings. And after accounting for these 2 factors, I observe that the most popular and the best movies have 7 overlaps, which makes sense.
I then implement 3 methods to perform SVD: self-written regular SVD, self-written SVD with added bias terms for each user and movie to model global tendencies of the various users and movies, and an off-the-shelf implementation "Surprise SVD". After obtaining the user and movie matrices, I project the matrices into 2D for easy visualizations. In general, I think the 2D visualizations are still very randomly distributed in space, but highly rated movies seem to cluster near the origin.
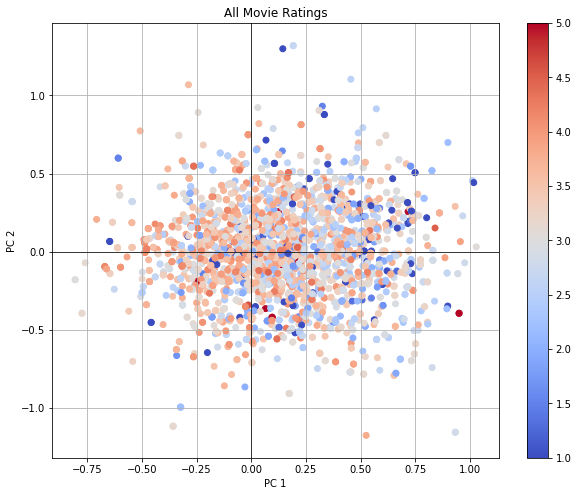
[Github: https://github.com/litingxiao/MovieLens-Viz] Back to top
High Frequency Price Prediction of Index Futures
In this project, I use 500ms aggregate high frequency market order book data of a futures contract to predict the probabilities of future 1-second price movements. To prevent timeseries modeling, the timestamps of the dataset are scrambled to make this a machine learning problem.
This binary classification problem that requires class probability outputs serves as a playground to familiarize me with the complete pipeline for such a machine learning project. I learned, implemented, and tested various models including linear regression with regularization, logistic regression with cross validation, support vector machine regressor, decision trees and random forests, and neural networks. Before model building and training, I explored the training set, filled in missing values, engineered new features, and scaled features. I also learned about model selection through different evaluation metrics.
[Github: https://github.com/litingxiao/HFT-kaggle]
Back to top